10 Causal inference
The world is full of weird and interesting relationships. Like this one.
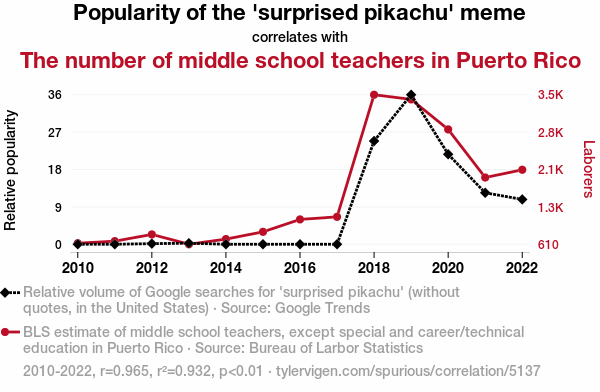
Which of these weird relationships are causal relationships and how can we tell? Here’s an AI-generated explanation for why the rise in the meme’s popularity might be responsible for the uptick in teachers in Puerto Rico:
As the ‘surprised Pikachu’ meme gained traction, it led to an uptick in internet usage. This surge in online activity put a higher demand on the telecommunication infrastructure in Puerto Rico. To meet this demand, more tech companies invested in the region, creating job opportunities. With the expanding job market, there was a need for additional educators to support the growing number of families relocating to Puerto Rico. As a result, the popularity of the meme indirectly contributed to an increase in the number of middle school teachers in Puerto Rico.

Causal inference is, in fact, a major area of research in statistics and machine learning. But we’ll just focus on the question of how people decide what causes what.
We’ll use a computational framework for making optimal probabilistic causal judgments called Bayesian networks, or Bayes nets for short. Comparing people’s judgments to Bayes net predictions allows us to see how optimal (or not) people are. Additionally, as we’ll see, Bayes nets are well suited for intervention, which is one way that people learn about causes.
10.1 Bayes nets ➡️
A Bayes net is a graph that describes the dependencies between all the variables in a situation.
For example, let’s make a Bayes net for the problem in Chapter 5 of inferring the bias of a coin. In that problem, there were three key variables: the bias \(\theta\), the total number of flips \(n\), and the number of heads \(k\). We can represent this as a Bayes net.
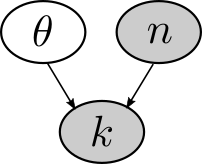
In Bayes nets, shaded nodes represent variables that are known or observed, and unshaded nodes represent variables that are unknown. We know how many times the coin was flipped and came up heads, but we don’t directly know the bias \(\theta\).
We could extend this Bayes net to capture the generalization problem of predicting the outcome of the next coin flip \(x\).
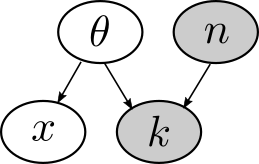
A complete Bayes net also specifies a probability distribution for each variable. In the example above, \(k\) is a function of \(\theta\) and \(n\). As we learned in Chapter 5, this is a Binomial distribution. We also need to specify a prior probability over any unknown variables, like \(\theta\). Previously we assumed it was distributed according to a Beta distribution. \(x\) is just a single coin flip – it’s a special case of a Binomial distribution called a Bernoulli distribution in which \(n = 1\). To sum up:
- \(\theta \sim \text{Beta}(\alpha, \beta)\)
- \(k \sim \text{Binomial}(n,\theta)\)
- \(x \sim \text{Binomial}(n=1, \theta)\)
10.2 Causal intervention 🪚
Consider the following two Bayes nets.
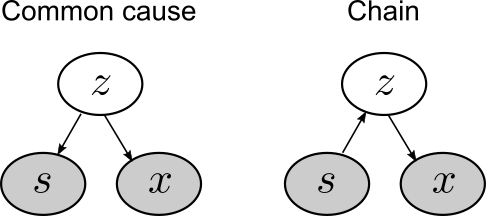
To be concrete, let’s say that variables \(s\) and \(x\) represent levels of hormones sonin and xanthan, respectively. Variable \(z\) is an unknown variable.
The common cause network is so-called because sonin (\(s\)) and xanthan (\(x\)) are both causally dependent on \(z\). The chain network is so-called because all the variables form a causal chain from \(s\) to \(x\) to \(z\). (Note the directions of the arrows in the two Bayes nets.)
Let’s see what kind of data these Bayes nets produce. Let’s assume that each root node of a network (\(z\) in the common cause, \(x\) in the chain) follows a normal distribution with mean 0 and SD 1. Each link in a network follows a normal distribution with mean equal to the value of its parent node and SD 1.
Because \(z\) represents an unknown variable, let’s plot just \(s\) and \(x\).
Clearly, the data isn’t identical in the two cases, but data generated by both Bayes nets results in a strong positive correlation between \(s\) and \(x\).
Imagine you didn’t know how this data was generated and you just got one of these plots. Could you use it to tell whether it was produced by a common cause structure or a chain structure?
Sorry, but no. 😔 Just knowing the data are positively correlated doesn’t give you enough information to figure out how \(s\) and \(x\) are causally related.
But what if you could manipulate the variables? That is, what if you could intervene on sonin levels and see what effect it had on xanthan levels?
- If you increase the sonin levels 📈 and the xanthan levels also increase 📈, then the causal structure must be a chain.
- If you increase the sonin levels 📈 and the xanthan levels don’t change ❌, then the causal structure can’t be a chain (and therefore must be a common cause, because that’s the only other option we’re considering).
10.2.1 Graph surgery
This intuition can be illustrated visually on the Bayes nets by performing “surgery” on the graphs. It works like this:
- Remove all incoming connections to the variable you’re intervening on.
- If there’s still a path between the variable you intervened on and another variable, then you should still expect those variables to be related.
Let’s apply this idea to our common cause and chain Bayes nets.
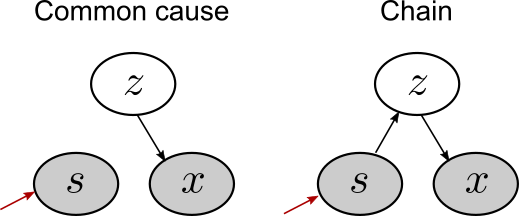
After intervening on sonin levels (\(s\)), we remove the connection to \(s\) in the common cause network, but no connections in the chain network. The resulting Bayes nets show why we should expect to see a resulting change in xanthan for the chain, but not the common cause.
10.2.2 Do people intuitively understand the logic of casual intervention?
A study by Michael Waldmann and York Hagmayer presented people with either the common cause or the chain structure. They were told that sonin and xanthan were hormone levels in chimps and they got some example data that allowed them to learn that the hormone levels were positively correlated.
Then they were either assigned to a doing or seeing condition. People in the doing condition were asked to imagine that 20 chimps had their sonin levels raised (or lowered). They then predicted how many of the chimps would have elevated xanthan levels. People in the seeing condition got essentially the same information but just learned that the chimps’ sonin levels were high (not that it had been intentionally raised).
Average results and model predictions are below.
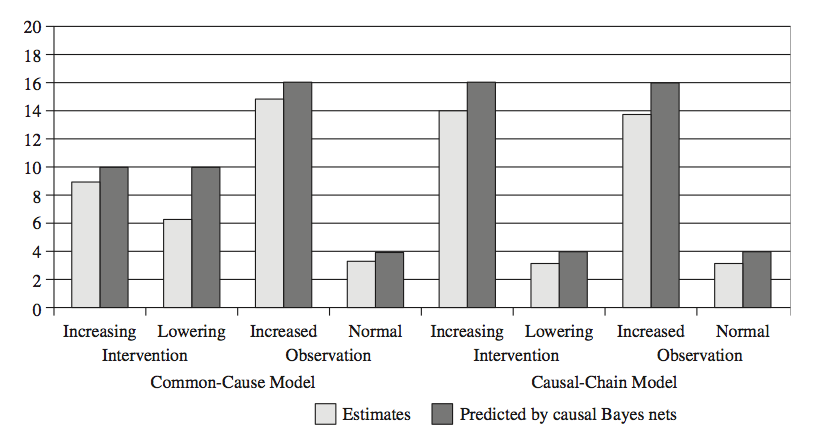
People’s judgments mostly followed those of the Bayes net model predictions. In the common cause case, when the sonin levels are artificially raised, the relationship between sonin and xanthan is decoupled, so the model reverts to a base rate prediction about xanthan levels (and so did people, for the most part). But when just observing elevated sonin levels, the model should expect the positive relationship to hold.
In the chain case, the predictions are the same for seeing or doing, because intervening doesn’t change anything about the relationship between sonin and xanthan. People’s judgments indicate that they understood this.
10.3 Causal structure and strength 🏗💪
Bayes nets can also account for how people judge the strength of evidence for a causal relationship after seeing some data. This was the idea that Tom Griffiths and Josh Tenenbaum explored in a 2005 computational study.
Here’s the basic problem they considered. Suppose researchers perform an experiment with rats to test whether a drug causes a gene to be expressed. A control group of rats doesn’t get the injection and the experimental group does. They record the number of rats in each group that express the gene.
Here are some possible results from an experiment with 8 rats in each group. The table shows how many rats in each group expressed the gene.
| Control 🐀 | Experimental 🐀 |
|---|---|
| 6/8 🧬 | 8/8 🧬 |
| 4/8 🧬 | 6/8 🧬 |
| 2/8 🧬 | 4/8 🧬 |
| 0/8 🧬 | 2/8 🧬 |
In each of these hypothetical experiments, how strongly would you say that the drug causes the gene to be expressed?
These are a few of the cases that were included in an experiment conducted by Marc Buehner and Patricia Cheng. Here’s the full set of averaged human results.
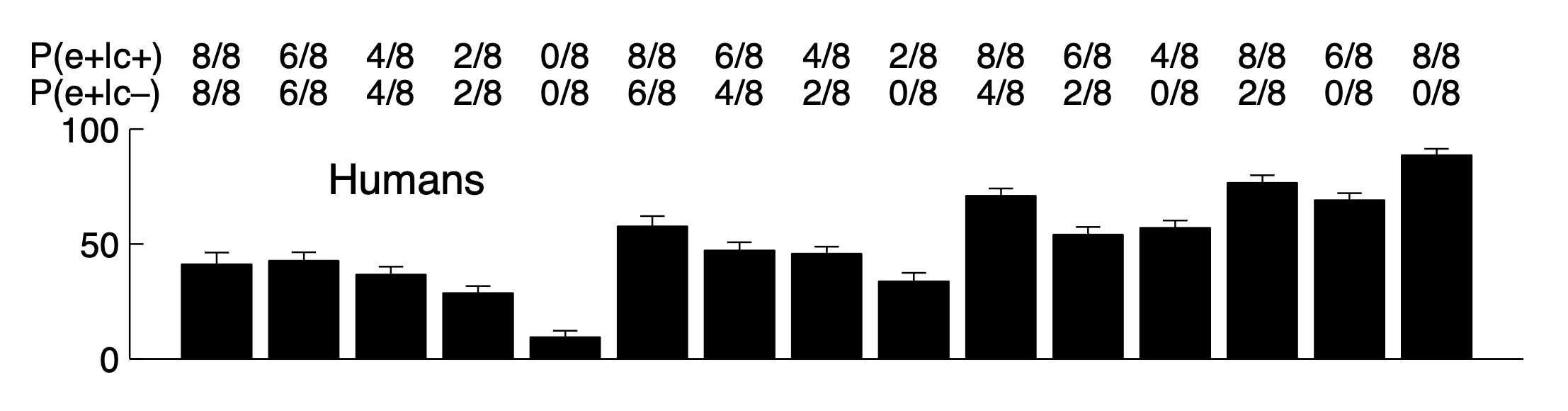
Focusing just on the cases in the table, on average, people judged that the drug was less likely to have a causal effect on the gene as the total number of rats expressing the gene decreased, even when the difference in number of rats expressing the gene between conditions was held constant.
10.3.1 The causal support model
Maybe people reason about these problems by performing a kind of model selection between the two Bayes nets below.
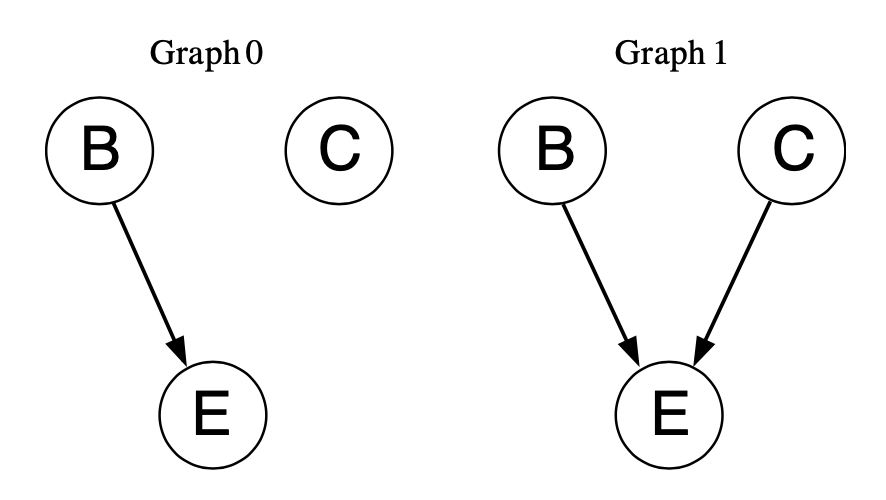
These Bayes nets each have three variables: an effect \(E\), a cause \(C\), and a background cause \(B\). For our problem, the effect and cause refer to the gene and the drug. The inclusion of the background cause is to account for unknown factors that might cause the gene to be expressed without the drug.
The problem people are faced with is deciding which of these two models is best supported by the data \(D\) – the number of times the effect occurred with and without the potential cause.
This can be done with Bayesian inference:
\[ P(\text{Graph } i) \propto P(D|\text{Graph } i) P(\text{Graph } i) \]
Because there are only two possible networks, we can compute the relative evidence for one Bayes net over the other as a ratio. We can then take the log of the expression to simplify it:
\[ \log \frac{P(\text{Graph } 1|D)}{P(\text{Graph } 0|D)} = \log \frac{P(D | \text{Graph } 1)}{P(D | \text{Graph } 0)} + \log \frac{P(\text{Graph } 1)}{P(\text{Graph } 0)} \]
Regardless of what prior probabilities we assign to the two graphs, the relative evidence for one graph over the other is entirely determined by the log-likelihood ratio. This is defined as causal support: \(\log \frac{P(D | \text{Graph } 1)}{P(D | \text{Graph } 0)}\).
Computing \(P(D | \text{Graph } 1)\) requires fully specifying the Bayes net. We’ll assume that \(P(E|B) = w_0\) and \(P(E|C) = w_1\). When both \(B\) and \(C\) are present, we’ll assume they contribute independently to causing \(E\), and therefore operate like a probabilistic OR function:
\[ P(e^+|b,c; w_o, w_1) = 1 - (1-w_0)^b (1-w_1)^c \]
Here, when the B or C are present, \(b\) and \(c\) are set to 1, and when they are absent, \(b\) and \(c\) are set to 0.
The likelihood for Graph 1 is therefore
\[ P(D | w_0, w_1, \text{Graph } 1) = \prod_{e,c} P(e|b^+,c; w_o, w_1)^{N(e,c)} \]
where the product is over the possible settings of \(e\) and \(c\) (effect absent/cause absent, effect absent/cause present, …) and the \(N(e,c)\) values are counts of times that these outcomes happened in the data \(D\).
Here’s a function to compute this. Run the code below to define the function.
Causal support doesn’t actually depend directly on the parameters \(w_0\) and \(w_1\). The reason is that we ultimately don’t care what the values of these parameters are because we just want to draw an inference at a higher level about the best-fitting Bayes net.
Mathematically speaking, \(w_0\) and \(w_1\) are averaged out of the model, an idea we first saw in Chapter 3. We can accomplish this using Monte Carlo approximation, introduced in Chapter 8.
Finally, let’s put it all together by writing a function that computes causal support.
Now let’s see what the model predicts for the four cases we considered earlier.
The labels on the x-axis indicate the control condition counts, followed by the experimental condition counts.
You can see that the model’s predictions largely follow the pattern in the data from earlier. The model favors Graph 1 in the two leftmost cases, is essentially uncertain in the third case, and begins to think the evidence favors no causal relationship in the rightmost case.
The rest of the Griffiths & Tenenbaum paper shows how causal support is able to capture some subtle aspects of people’s causal judgments that other models that don’t incorporate both structure and strength fail to capture.